Just before 8:00 a.m. local time on December 26, 2004, people in southeast Asia were starting their days when the third strongest recorded earthquake in history ripped a 1,500-kilometer tear in the ocean floor off the coast of the Indonesian island of Sumatra.
The earthquake lasted between 8 and 10 minutes (one of the longest ever recorded), and lifted the ocean floor several meters, creating a tsunami with 30-meter waves that devastated whole communities. The event caused nearly 200,000 deaths across 15 countries, and released as much energy above and below ground as multiple centuries of US energy usage.
The Sumatra-Andaman Earthquake, as it is called, was as surprising as it was violent. Despite major advancements in earthquake monitoring and warning systems over the last 50 years, earth scientists were unable to predict it because relatively little data exists about such large-scale seismological events. Researchers have a wealth of information related to semi-regular, lower-to-medium-strength earthquakes, but disasters such as the Sumatra-Andaman — events that only happen every couple hundred years — are too rare to create reliable data sets.
In order to more fully understand these events, and hopefully provide better prediction and mitigation methods, a team of researchers from the Ludwig-Maximilians-Universität Munich (LMU) and Technical University of Munich (TUM) is using supercomputing resources at the Leibniz Supercomputing Centre (LRZ) to better understand these rare, extremely dangerous seismic phenomena.
“Our general motivation is to better understand the entire process of why some earthquakes and resulting tsunamis are so much bigger than others,” said TUM Professor Dr. Michael Bader. “Sometimes we see relatively small tsunamis when earthquakes are large, or surprisingly large tsunamis connected with relatively small earthquakes. Simulation is one of the tools to get insight into these events.”
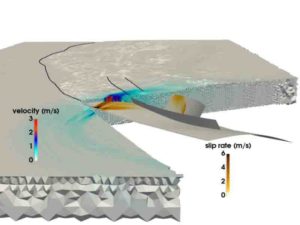
The team strives for “coupled” simulations of both earthquakes and subsequent tsunamis. It recently completed its largest earthquake simulation yet. Using the SuperMUC supercomputer at LRZ, the team was able to simulate 1,500 kilometers of non-linear fracture mechanics — the earthquake source — coupled to seismic waves traveling up to India and Thailand over a little more than 8 minutes of the Sumatra-Andaman earthquake. Through several in-house computational innovations, the team achieved a 13-fold improvement in time to solution. In recognition of this achievement, the project was nominated for the best paper award at SC17, one of the world’s premier supercomputing conferences, held this year on November 12-17 in Denver, Colorado.
Megathrust earthquakes, massive scale simulations
Earthquakes happen as rock below Earth’s surface breaks suddenly, often as a result of the slow movement of tectonic plates.
One rough predictor of an ocean-based earthquake’s ability to unleash a large tsunami is whether plates are grinding against one another or colliding head-on. If two or more plates collide, one plate will often force the other below it. Regions where this process occurs are called subduction zones and can host very large, shallowly dipping faults — so called “megathrusts.” Energy release across such huge zones of weakness tends to create violent tsunamis, as the ocean floor rises a significant amount, temporarily displacing large amounts of water.
Until recently, though, researchers doing computational geophysics had great difficulties simulating subduction earthquakes at the necessary level of detail and accuracy. Large-scale earthquake simulations are difficult generally, but subduction events are even more complex.
“Modeling earthquakes is a multiscale problem in both space and time,” said Dr. Alice Gabriel, the lead researcher from the LMU side of the team. “Reality is complex, meaning that incorporating the observed complexity of earthquake sources invariably involves the use of numerical methods, highly efficient simulation software, and, of course, high-performance computing (HPC). Only by exploiting HPC can we create models that can both resolve the dynamic stress release and ruptures happening with an earthquake while also simulating seafloor displacement over thousands of kilometers.”
When researchers simulate an earthquake, they use a computational grid to divide the simulation into many small pieces. They then compute specific equations for various aspects of the simulation, such as generated seismic shaking or ocean floor displacement, among others, over “time steps,” or simulation snapshots over time that help put it in motion, much like a flip book.
The finer the grid, the more accurate the simulation, but the more computationally demanding it becomes. In addition, the more complex the geometry of the earthquake, the more complex the grid becomes, further complicating the computation. To simulate subduction earthquakes, computational scientists have to create a large grid that can also accurately represent the very shallow angles at which the two continental plates meet. This requires the grid cells around the subduction area to be extra small, and often slim in shape.
Unlike continental earthquakes, which have been better documented through computation and observation, subduction events often happen deep in the ocean, meaning that it is much more difficult to constrain a simulation by ground shaking observations and detailed, reliable data from direct observation and laboratory experiments.
Furthermore, computing a coupled, large-scale earthquake-tsunami simulation requires using data from a wide variety of sources. Researchers must take into account the seafloor shape, the shape and strength of the plate boundary ruptured by the earthquake and the material behaviour of Earth’s crust at each level, among other aspects. The team has spent the last several years developing methods to more efficiently integrate these disparate data sources into a consistent model.
To reduce the enormous computing time, the team exploited a method called “local time stepping.” In areas where the simulations require much more spatial detail, researchers also must “slow down” the simulation by performing more time steps in these areas. Other sections that require less detail may execute much bigger — and thus — far fewer time steps.
If the team had to run its entire simulation at a uniform small time step, it would have required roughly 3 million individual iterations. However, only few cells of the computational grid required this time step size. Major parts could be computed with much larger time steps, some requiring only 3000 time steps. This reduced the computational demand significantly and led to much of the team’s 13-fold speedup. This advancement also led to the team’s simulation being the largest, longest first-principles simulation of an earthquake of this type.
Forward motion
Due to its close collaboration with LRZ staff, the team had opportunities to use the entire SuperMUC machine for its simulations. Bader indicated that these extremely large-scale runs are invaluable for the team to gain deeper insights in its research. “There is a big difference if you run on a quarter of a machine or a full machine, as that last factor of 4 often reveals the critical bottlenecks,” he said.
The team’s ability to take full advantage of current-generation supercomputing resources has it excited about the future. It’s not necessarily important that next-generation machines offer the opportunity for the LMU-TUM researchers to run “larger” simulations — current simulations can effectively simulate a large enough geographic area. Rather, the team is excited about the opportunity to modify the input data and run many more iterations during a set amount of computing time.
“We have been doing one individual simulation, trying to accurately guess the starting configuration, such as the initial stresses and forces, but all of these are still uncertain,” Bader said. “So we would like to run our simulation with many different settings to see how slight changes in the fault system or other factors would impact the study. These would be larger parameter studies, which is another layer of performance that a computer would need to provide.”
Gabriel also mentioned that next-generation machines will hopefully be able to simulate urgent, real-time scenarios that can help predict hazards as they relate to likely aftershock regions. The team is excited to see the next-generation architectures at LRZ and the other Gauss Centre for Supercomputing centres, the High-Performance Computing Center Stuttgart and the Jülich Supercomputing Centre.
In Bader’s view, the team’s recent work not only represents its largest-scale simulation to date, but also the increasingly strong collaboration between the domain scientists and computational scientists in the group. “This paper has a strong seismology component and a strong HPC component,” he said. “This is really a 50-50 paper for us. Our collaboration has been going nicely, and it is because it isn’t about getting ours or theirs. Both groups profit, and this is really nice joint work.”
This work was carried out using Gauss Centre for Supercomputing resources based at the Leibniz Supercomputing Centre.
Note: The above post is reprinted from materials provided by Gauss Centre for Supercomputing.









{kind=link}